Content Discovery¶
Contents
- Content Discovery
- Querying the SOLR Index
- System Metadata Index Properties
- Properties of the Index Derived from Resource Maps
- Values Extracted from Science Metadata
- Date Representations in Science Metadata Documents
- Science metadata examples
- Standard Specific Metadata Extraction Notes
- Attribute Descriptions and Notes
- Creating Citations from Index Fields
Searching for content is a functionality that is primarily supported by Coordinating Nodes, programmatically through the CN_read.search method, and through a web browser interface that connects through a user interface implemented by Mercury which utilizes a SOLR index to support search operations.
This document describes the properties of the SOLR index, how it is populated, and how it can be used to support programmatic search and introspection into the DataONE holdings.
The SOLR index is populated from content that is copied to Coordinating Nodes, that is System Metadata, Science Metadata and Resource Maps. Each index entry represents information about the information referenced by a single identifier (PID). For PIDs that refer to science data objects the index entry will be constructed from system metadata and zero or more resource maps that reference the object. If a PID identifies a science metadata object, the index entry will have fields populated with content extracted from the system metadata for the object, the science metadata document and zero or more resource maps that reference the science metadata. Similarly, if the PID identifies a resource map, then the index entry fields for that PID will be populated by the System Metadata and resource map values for that PID.
The general sequence for indexing content is illustrated in Figure 1 below.
The general process of indexing content involves retrieving a System Metadata document, parsing system metadata properties such as permission rules to generate a SOLR index document, then optionally adding to the document if the PID refers to a science metadata or resource map object. The general sequence of operations is outlined in Figure 1. If the PID refers to a resource map, then it is necessary to update the documents and isDocumentedBy properties of the Science Metadata and data objects that appear in the data package defined by the Resource Map.
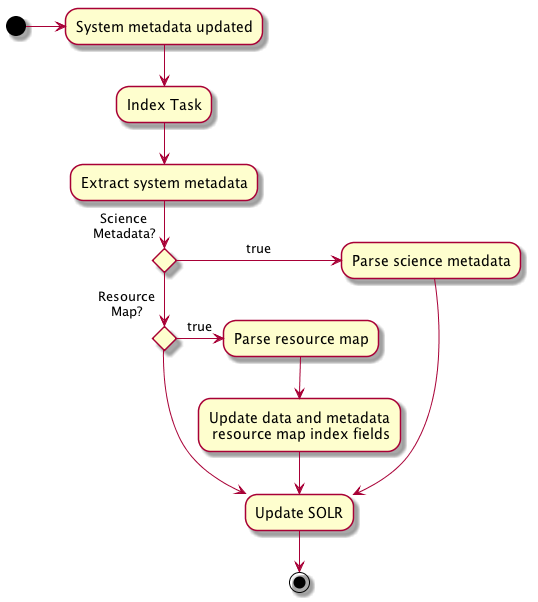
A full list of index fields is provided in Table 4 below.
Querying the SOLR Index¶
The SOLR query syntax is based on the Lucene query syntax and adds a couple of extensions. The SOLR search index is exposed directly as a SOLR search service with the base url of:
http(s)://server.name/solr/
System Metadata Index Properties¶
The main goals for indexing system metadata include:
- Support access control rules for search results
- Support efficient discovery of objects by their properties
Table 1 provides a list of SOLR attributes that are populated by values taken from System Metadata.
Table 1. Elements derived from System Metadata and available for all objects. “Multi” fields may be populated with more than a single value per document (PID) indexed.
Populating Permission Fields¶
This process is fairly straight forward, and requires simply de-duping entries so that each of the permission fields contains a distinct list of subjects granted that permission. If the DataONE public user is present in the read permissions, then the isPublic field is set to True.
Example Queries¶
The following provide some example queries that may be issued directly against the SOLR index operating on the Coordinating Nodes. Note that search terms must be properly escaped for the SOLR query syntax, and additionally if submitted directly as part of a URL, must also be properly URL escaped.
Index entries that match PID (should be at most one match):
id:"PID"
where PID = identifier of object being located
Index entries with PID that starts with “some_prefix”:
id:"some_prefix*"
Index entries that match a particular format id:
formatId:"format_a"
where format_a = the formatId being located
Entries with formatId matching “fmtid_1” or “fmtid_2”:
formatId:"fmtid_1" || formatId:"fmtid_2"
Entries with byte size less than or equal to 10000:
size:[* TO 10000]
Entries with byte size less than 10000:
size:{* TO 10000}Objects modified before 09:56:04 on 2012-01-03 UTC:
datemodified:{* TO 2012-01-03T09:56:04.000Z}Objects modified less than 10 minutes ago:
datemodified:[NOW-10MINUTE TO *]
Objects of a formatId equal to “format_a” and modified within one day:
formatId:"format_a" AND datemodified:[NOW-1DAY TO *]
Metadata associated with data objects of relevance to Photosynthesis:
photosynthesis AND documents:[* TO *]
Properties of the Index Derived from Resource Maps¶
Table 2 provides a list of SOLR attributes that are populated by values obtained by parsing resource map objects.
Table 2. Elements derived from Resource Map documents. “Multi” fields may be populated with more than a single value per document (PID) indexed.
| Attribute | Type | Multi? | Content Origin |
|---|---|---|---|
| SearchMetadata.isDocumentedBy | string | Yes | |
| SearchMetadata.documents | string | Yes | |
| SearchMetadata.resourceMap | string | Yes |
Populating Object Relation Fields¶
The fields resourceMap, documents, and isDocumentedBy contain identifiers of other objects in the DataONE system related to the subject of the current record. These relationships are recorded in OAI-ORE resource map documents as described in the section Data Packaging. Since the values for these fields are contained in resource maps, it is necessary to build these fields in progression as additional resource maps are synchronized with the coordinating nodes.
For each object, a query is issued against the index to retrieve the list of resource maps in which the object identifier is present, enabling population of the resourceMaps field for the object. Each of those resource maps is examined to obtain the list of identifiers for the documents field if the object is science metadata, and the isDocumentedBy field if the object is data.
Example Sequence for Index Population
The following sequence steps through the generation of index entries for three data packages, providing an example of how the index entries are updated depending on relationships between the objects being added.
Adding Package 1¶
![digraph RM1 {
graph [rankdir="LR", label="Package 1"];
A [shape=folder];
B [shape=note];
C [shape=oval];
A -> B;
A -> C;
}](../_images/graphviz-c97b8760b9ca8e6070afbd1f6c2a2041e6d9d5d0.png)
A simple data package with a Resource Map A indicating that the metadata document B and the data object C together form a data package, and that B documents C and that C isDocumentedBy B.
Index entries after Package 1 is added.
PID resourceMaps documents isDocumentedBy A B A C C A B
Adding Package 2¶
![digraph RM1 {
graph [rankdir="LR", label="Package 2"];
D [shape=folder];
B [shape=note];
E [shape=oval];
D -> B;
D -> E;
}](../_images/graphviz-0269dd166c07690c658402e4e977f06cc5aec85c.png)
A simple data package with a Resource Map D indicating that the metadata document B and the data object E together form a data package, and that B documents E and that E isDocumentedBy B. Note that the metadata document B is also used in Package 1.
Index entries after package 2 is added. New entries and changes to existing are indicated in bold.
PID resourceMaps documents isDocumentedBy A B A, D C, E C A B D E D B
Adding Package 3¶
![digraph RM1 {
graph [rankdir="LR", label="Package 3"];
F [shape=folder];
G [shape=note];
D [shape=folder];
F -> G;
F -> D;
}](../_images/graphviz-127142dfcd7cd6cb31c117fa142e0babfe2fc643.png)
A data package that references another, already indexed data package (represented by the Resource Map D) as its data object.
Index entries after package 3 is added. New entries and changes to existing are indicated in bold.
PID resourceMaps documents isDocumentedBy A B A, D C, E C A B D F G E D B F G F D
Limitations of Multi-Valued Fields in SOLR¶
Multi-valued fields in SOLR have an internal representation that can be likened to a delimited concatenation of all the values for the field. The fields have a configurable limit to the maximum field size, and this limit may be encountered in the various entries such as the permission fields or object relation fields where a potentially large number of subjects or identifiers may be stored. Further research has indicated this problem is unlikely since simply increasing the SOLR maxFieldLength configuration value will enable larger field content, with examples in the wild of several thousand entries equivalent to DataONE identifiers in a single field.
Values Extracted from Science Metadata¶
Indexing the system metadata entries provides a mechanism for selection of content using low level attributes of the objects such as the type, size and relationships, however is not useful for locating content relevant to a particular topic or purpose. The science metadata contains such information and the index records associated with these documents contain additional information described below.
The initial web user interface to DataONE utilizes the Mercury system. This in turn relies upon a SOLR index to support the search, faceting, and sub-setting operations that are exposed through Mercury. The underlying SOLR index is also exposed through as an API, so other clients (such as the file system driver) can leverage the search capabilities thus provided.
The remainder of this document describes the search properties that are extracted from the various formats and syntaxes of of science metadata that are supported by the DataONE indexing system.
Table 3. Index fields populated from science metadata documents. “Multi” fields may be populated with more than a single value per document (PID) indexed.
| Field | Type | Multi? | Description |
|---|---|---|---|
| SearchMetadata.abstract | text | No | The full text of the abstract as provided in the science metadata document. |
| SearchMetadata.author | string | No | Principle Investigator (PI) / Author as listed in the metadata document. |
| SearchMetadata.authorLastName | string | Yes | The LAST name(s) of the author(s) |
| SearchMetadata.beginDate | date | No | The starting date of the temporal range of the content described by the metadata document. |
| SearchMetadata.class | string | Yes | Taxonomic class name(s) |
| SearchMetadata.contactOrganization | string | No | Name of the organization to contact for more information about the dataset |
| SearchMetadata.decade | string | No | The latest decade that is covered by the dataset, expressed in the form “1999-2009” |
| SearchMetadata.eastBoundCoord | sfloat | No | Eastern most longitude of the spatial extent, in decimal degrees, WGS84 |
| SearchMetadata.edition | text | No | The version or edition number of the item described. |
| SearchMetadata.endDate | date | No | The ending date of the temporal range of the content described by the metadata document. |
| SearchMetadata.family | string | Yes | Taxonomic family name(s) |
| SearchMetadata.fileID | string | No | Contains the CNRead.resolve() URL for the object ONLY if the object is a science metadata object. |
| SearchMetadata.fullText | text | No | Full text of the metadata record, used to support full text searches |
| SearchMetadata.gcmdKeyword | text | Yes | Keywords drawn from the GCMD controlled vocabulary |
| SearchMetadata.genus | string | Yes | Taxonomic genus name(s) |
| SearchMetadata.geoform | string | No | The name of the general form in which the item’s geospatial data is presented |
| SearchMetadata.investigator | string | Yes | Name of the investigator(s) responsible for developing the dataset and associated content. |
| SearchMetadata.isSpatial | string | No | Set to “Y” for records that contain spatial information |
| SearchMetadata.keywords | string | Yes | Keywords recorded in the science metadata document. These may be controlled by the generator of the metadata or by the metadata standard of the document, but are effectively uncontrolled within the DataONE context. |
| SearchMetadata.kingdom | string | Yes | Taxonomic kingdom(s) |
| SearchMetadata.LTERSite | string | No | Data provider organization identifier, for sources within the LTER network. |
| SearchMetadata.noBoundingBox | string | No | Set to “Y” if there is no bounding box information available (i.e., the east, west, north, south most coordinates) |
| SearchMetadata.northBoundCoord | sfloat | No | Northern most latitude of the spatial extent, in decimal degrees, WGS84 |
| SearchMetadata.ogcUrl | text | No | URL for Open Geospatial Web service if available. |
| SearchMetadata.order | string | Yes | Taxonomic order name(s) |
| SearchMetadata.origin | string | Yes | Investigator or Investigator organization name. |
| SearchMetadata.originator | string | Yes | Investigator or Investigator organization name. Derived by normalizing origin. |
| SearchMetadata.parameter | string | Yes | A characteristic, or variable, that is measured or derived as part of data-collection activities. |
| SearchMetadata.phylum | string | Yes | Taxonomic phylum (or division) name(s) |
| SearchMetadata.placeKey | text | Yes | A place name keyword, assigned by the metadata creator. It is one keyword from the thesaurus named in <placekt> |
| SearchMetadata.presentationCat | string | No | Type of data being preserved (maps, text, etc.) |
| SearchMetadata.project | string | No | The authorized name of a research effort for which data is collected. This name is often reduced to a convenient abbreviation or acronym. All investigators involved in a project should use a common, agreed-upon name. |
| SearchMetadata.pubDate | date | No | Publication date for the dataset (this may or may not be coincident with when the content is added to DataONE). |
| SearchMetadata.purpose | text | No | The “Purpose” describes the “why” aspects of the data set (For example, why was the data set created?). |
| SearchMetadata.sensor | string | Yes | Also called “instrument.” A device that is used for collecting data for a data set. |
| SearchMetadata.site | string | Yes | The name or description of the physical location where the data were collected |
| SearchMetadata.source | string | Yes | Also called “platform.” The mechanism used to support the sensor or instrument that gathers data |
| SearchMetadata.southBoundCoord | sfloat | No | Southern most latitude of the spatial extent, in decimal degrees, WGS84 |
| SearchMetadata.species | string | Yes | Taxonomic species name(s) |
| SearchMetadata.term | string | Yes | A secondary subject area within which parameters can be categorized. Approved terms include “agricultural chemicals” and “atmospheric chemistry,” among many others. When entering a term in the LandVal Metadata Editor, users should select a standard expression from the pick list for terms if at all possible. |
| SearchMetadata.title | string | No | Title of the dataset as recorded in the science metadata. |
| SearchMetadata.topic | string | Yes | The most general subject area within which a parameter is categorized. Approved topics include “agriculture,” “atmosphere,” and “hydrosphere,” among others. |
| SearchMetadata.webUrl | string | Yes | Link to the investigator’s web-site. |
| SearchMetadata.westBoundCoord | sfloat | No | Western most longitude of the spatial extent, in decimal degrees, WGS84 |
| SearchMetadata.keyConcept | string | Yes | Terms drawn from a controlled vocabulary of concepts that are applicable to the content described by the metadata document. |
| SearchMetadata.namedLocation | string | Yes | The name of the location(s) relevant to the content described by the metadata document. |
| SearchMetadata.relatedOrganizations | string | Yes | Organizations that played an indirect role in the development of the data set and metadata that should be cited or mentioned as contributing to the development of the data or metadata. |
| SearchMetadata.scientificName | string | Yes | Taxonomic scientific name(s) at the most precise level available for the organisms of relevance to the dataset |
Date Representations in Science Metadata Documents¶
The following are examples of date values extracted from FGDC, ISO-19115, and EML science metadata documents currently in use. The literal value appearing in the document and the interpreted date value are shown.
Examples of date values appearing in FGDC <pubdate>:
| Value | Interpreted Value |
|---|---|
| Unknown | Null |
| unknown | Null |
| Unpublished material | Null |
| unpublished material | Null |
| 1993 | 1993-01-01 00:00:00Z |
| 199607 | 1996-07-01 00:00:00Z |
| 20000101 | 2000-01-01 00:00:00Z |
| 19981231 | 1998-12-31 00:00:00Z |
| 196820405 | 1968-01-01 00:00:00Z |
| 1992 onwards | 1992-01-01 00:00:00Z |
| 1989 and 1990 | 1989-01-01 00:00:00Z |
| varies | Null |
| Present | Null |
| 1995/1996 | 1995-01-01 00:00:00Z |
| 1991-1992 | 1991-01-01 00:00:00Z |
| variouis | Null |
| April 1999 | 1999-04-01 00:00:00Z |
| 1980 on | 1980-01-01 00:00:00Z |
| 2005-06-24 | 2005-06-24 00:00:00Z |
| NA | Null |
| 1990- [unpublished annual reports] | 1990-01-01 00:00:00Z |
| November, 1994 | 1994-11-01 00:00:00Z |
Examples of date values appearing in ISO-19115 <gco:Date>:
| Value | Interpreted Value |
|---|---|
| 1999 | 1999-01-01 00:00:00Z |
| 2010-03-03 | 2010-03-03 00:00:00Z |
Examples of date values appearing in EML <calendarDate>:
| Value | Interpreted Value |
|---|---|
| 2002-06-20 | 2002-06-20 00:00:00Z |
| 1998 | 1998-01-01 00:00:00Z |
| 2004-02-13 | 2004-02-13 00:00:00Z |
Attribute Descriptions and Notes¶
A list of all fields in search index, their origin and brief description. Source column indicates which DataONE content the values are retrieved from: Y = System Metadata, S = Science Metadata, R = Resource Map, and C = copied internally by the search index.
| Index Field | Multi? | Source | Description |
|---|---|---|---|
|
No | S | The full text of the abstract as provided in the science metadata document. |
| No | S | Principle Investigator (PI) / Author as listed in the metadata document. | |
| No | Y | The node Id of the authoritative Member Node for the object. | |
| Yes | S | The LAST name(s) of the author(s) | |
|
No | S | The starting date of the temporal range of the content described by the metadata document. |
|
Yes | Y | A multi-valued field that contains the node Ids of member nodes that are blocked from holding replicas of this object. |
|
Yes | Y | List of subjects (groups and individuals) that have change permission on PID. |
|
No | Y | The checksum for the object |
|
No | Y | Algorithm used for generating the object checksum |
|
Yes | S | Taxonomic class name(s) |
|
No | S | Name of the organization to contact for more information about the dataset |
|
No | C | Copy from contactOrganization |
|
No | Y | The node Id of the member node that originally contributed the content. |
|
No | Y | The URL that can be used to resolve the location of the object given its PID. |
|
No | Y | The date and time when the object system metadata was last updated. |
|
No | Y | The date and time when the object was uploaded to the Member Node. |
|
No | S | The latest decade that is covered by the dataset, expressed in the form “1999-2009” |
|
Yes | R | Lists all PIDs that this object describes. Obtained by parsing all resource maps in which this object is referenced. Not set for data or resource map objects. |
|
No | S | Eastern most longitude of the spatial extent, in decimal degrees, WGS84 |
|
No | S | The version or edition number of the item described. |
|
No | S | The ending date of the temporal range of the content described by the metadata document. |
|
Yes | S | Taxonomic family name(s) |
|
No | S | Contains the CNRead.resolve() URL for the object ONLY if the object is a science metadata object. |
|
No | Y | The format identifier indicating the type of content this record refers to. |
|
No | S | Full text of the metadata record, used to support full text searches |
|
Yes | S | Keywords drawn from the GCMD controlled vocabulary |
|
Yes | S | Taxonomic genus name(s) |
|
No | S | The name of the general form in which the item’s geospatial data is presented |
|
No | Y | The identifier of the object being indexed. |
|
No | C | Copy from id |
|
Yes | S | Name of the investigator(s) responsible for developing the dataset and associated content. |
|
Yes | C | Copy from investigator |
|
Yes | R | Lists all PIDs that describe this object. Obtained by parsing all resource maps in which this object is referenced. |
|
No | Y | Set to True if the DataONE public user is present in the list of subjects with readPermission on PID. |
|
No | S | Set to “Y” for records that contain spatial information |
|
Yes | S | Terms drawn from a controlled vocabulary of concepts that are applicable to the content described by the metadata document. |
|
Yes | S | Keywords recorded in the science metadata document. These may be controlled by the generator of the metadata or by the metadata standard of the document, but are effectively uncontrolled within the DataONE context. |
|
Yes | C | Copy from keywords |
|
Yes | S | Taxonomic kingdom(s) |
|
No | S | Data provider organization identifier, for sources within the LTER network. |
|
Yes | S | The name of the location(s) relevant to the content described by the metadata document. |
|
No | S | Set to “Y” if there is no bounding box information available (i.e., the east, west, north, south most coordinates) |
|
No | S | Northern most latitude of the spatial extent, in decimal degrees, WGS84 |
|
No | Y | Requested number of replicas for the object |
|
No | Y | If set, indicates the object that this record obsoletes. |
|
No | S | URL for Open Geospatial Web service if available. |
|
Yes | S | Taxonomic order name(s) |
|
Yes | S | Investigator or Investigator organization name. |
|
Yes | S | Investigator or Investigator organization name. Derived by normalizing origin. |
|
Yes | C | Copy from originator |
|
Yes | C | Copy from origin |
|
Yes | S | A characteristic, or variable, that is measured or derived as part of data-collection activities. |
|
Yes | C | Copy from parameter |
|
Yes | S | Taxonomic phylum (or division) name(s) |
|
Yes | S | A place name keyword, assigned by the metadata creator. It is one keyword from the thesaurus named in <placekt> |
|
Yes | Y | A list of member node identifiers that are preferred replication targets for this object. |
|
No | S | Type of data being preserved (maps, text, etc.) |
|
No | S | The authorized name of a research effort for which data is collected. This name is often reduced to a convenient abbreviation or acronym. All investigators involved in a project should use a common, agreed-upon name. |
|
No | C | Copy from project |
|
No | S | Publication date for the dataset (this may or may not be coincident with when the content is added to DataONE). |
|
No | S | The “Purpose” describes the “why” aspects of the data set (For example, why was the data set created?). |
|
Yes | Y | List of subjects (groups and individuals) that have read permission on PID. |
| Yes | S | Organizations that played an indirect role in the development of the data set and metadata that should be cited or mentioned as contributing to the development of the data or metadata. | |
|
Yes | Y | One or more node Ids holding copies of the object. |
|
No | Y | True if this object can be replicated. |
|
Yes | R | List of resource map PIDs that reference this PID. |
|
No | Y | The Subject that acts as the rights holder for the object. |
|
Yes | S | Taxonomic scientific name(s) at the most precise level available for the organisms of relevance to the dataset |
|
Yes | S | Also called “instrument.” A device that is used for collecting data for a data set. |
|
Yes | C | Copy from sensor |
|
Yes | S | The name or description of the physical location where the data were collected |
|
Yes | C | Copy from site |
|
No | Y | The size of the object, in bytes. |
|
No | C | Copy from id |
|
Yes | S | Also called “platform.” The mechanism used to support the sensor or instrument that gathers data |
|
Yes | C | Copy from source |
|
No | S | Southern most latitude of the spatial extent, in decimal degrees, WGS84 |
|
Yes | S | Taxonomic species name(s) |
|
No | Y | The Subject name of the original submitter of the content to DataONE. |
|
Yes | S | A secondary subject area within which parameters can be categorized. Approved terms include “agricultural chemicals” and “atmospheric chemistry,” among many others. When entering a term in the LandVal Metadata Editor, users should select a standard expression from the pick list for terms if at all possible. |
|
Yes | C | Copy from term |
|
Yes | C | contactOrganization, datasource, decade, features, fileID, fullText, gcmdKeyword, geoform, id, includes, investigator, keywords, LTERSite, manu, name, origin, originator, parameter, placeKey, presentationCat, project, purpose, sensor, site, source, term, title, topic |
|
No | S | Title of the dataset as recorded in the science metadata. |
|
No | C | Copy from title |
|
No | C | Copy from title |
|
Yes | S | The most general subject area within which a parameter is categorized. Approved topics include “agriculture,” “atmosphere,” and “hydrosphere,” among others. |
|
Yes | C | Copy from topic |
|
No | C | Copy from dateuploaded |
|
Yes | S | Link to the investigator’s web-site. |
|
No | S | Western most longitude of the spatial extent, in decimal degrees, WGS84 |
|
Yes | Y | List of subjects (groups and individuals) that have write permission on PID. |
Creating Citations from Index Fields¶
Table 3. Cross reference of index fields and elements useful in citation best practices as exemplified in the interagency data stewardship wiki page of ESIP. * = Mandatory (if applicable). COinS tags provide a mechanism of embedding Z39.88-2004 elements in HTML for consumption by citation manager tools.
| Citation Element | FGDC CSDGM field | DataCite Metadata Scheme ID and Property | DataONE Index Field | COinS Tag |
|---|---|---|---|---|
| Author or Creator* | idinfo > citation > citeinfo > “origin” | 2 Creator* | author | rft.creator |
| Release Date* | idinfo > citation > citeinfo > “pubdate” and sometimes “othercit” | 5 PublicationYear* | datePublished | rft.date |
| Title* | idinfo > citation > citeinfo > “title” and possibly “edition” | 3 Title* | title | rft.title |
| Version* | 15 Version | See notes below. | ||
| Archive and/or Distributor* | idinfo > citation > citeinfo > “publish” | 4 Publisher* | See notes below. | rft.publisher |
| Locator, Identifier, or Distribution Medium* | idinfo > citation > citeinfo > “othercit” or “onlink” | 1 Identifier* | pid | rft.identifier |
| Access Date and Time* | not applicable | 8 Date | perhaps dateUploaded | |
| Subset Used | not applicable | 12 RelatedIdentifier DataCite recommends obtaining an identifier for any subset that needs to be cited as well as an identifier for the larger whole. | perhaps a reference to the resource map? | |
| Editor or Other Important Role | idinfo > citation > citeinfo > “origin” | 7 Contributor | See notes below. | rft.source |
| Publication Place | idinfo > citation > citeinfo > “pubplace” | 17 Description | See notes below. | |
| Distributor, Associate Archive, or other Institutional Role | idinfo > citation > citeinfo > “othercit” | 7 Contributor or possibly 4 Publisher | “http://dataone.org“ | |
| Data Within a Larger Work | idinfo > citation > citeinfo > “othercit” or “lworkcit” | 12 RelatedIdentifier | perhaps a reference to the resource map? | |
| keyWord | rft.subject | |||
| abstract | rft.description | |||
| object format name, or “data” | “metadata” | “resource map” | rft.type | |||
| object format type | rft.format | |||
| constructed from bounding box | rft.coverage |
Notes
| Version: | There is no clear recommendation on how to express version. For an object with a linear revision history (A is obsoleted by B is obsoleted by C), object C might be considered to have a version of “2”. However, it is possible for an object to have a tree lineage (A1 and A2 are obsoleted by B1, and B1, A3 and Z are obsoleted by C). A suggestion for a version indicator in this case may be the total number of parent objects, 5 in this case. Another option may be to indicate the number of contributing objects at each revision, 1.1 in the first case, and 2.3 in the second. |
|---|---|
| Publisher: | The publisher in DataONE may in some cases be the origin member node, however this will not always be the case. For example, many data sets in the KNB are published by LTER, though KNB would be the member node. Where possible the publisher information should be pulled from the science metadata, though this may be complicated where multiple data and metadata entries occur within a data package and there are several publishers listed. In this case, a simple concatenation of the publishers (semi-colon + space delimited) may be sufficient. |
| Date: | In the DataCite 2.2 document, a mapping between Date and the dcterms:date is suggested. The description of dcterms:date is “A point or period of time associated with an event in the lifecycle of the resource.” In DataONE there are two main dates related to an object, when the content is added to the system, and when the properties of the object (access control, and so forth) are modified. Since the content of the object does not change once submitted to DataONE, the SystemMetadata.dateUploaded value seems appropriate here, expressed as dateUploaded in the search index. |
| Subset Used: | DataONE does not provide a mechanism for identifying sets of information other than through resource maps which describe data packages. It is possible that a resource map may contain references to additional resource maps, conceptually equivalent to subsets of content. The simplest option here would be to use the identifier of the resource map object describing the package in question. |
| Contributor: | Described in DataCite 2.2 as “The institution or person responsible for collecting, creating, or otherwise contributing to the development of the dataset”, this optional element can be populated by the citeinfo/origin element from FGDC. |
| Publication Place: | |
| In CSDGM, “the name of the city (and state or province, and country, if needed to identify the city) where the data set was published or released”. | |
| Data Within a Larger Work: | |
| This is similar to the “Subset Used” entry except in the other direction of containment. The identifier of the containing resource map relevant to the current package should be used. | |
![]()
Table Of Contents
- Content Discovery
- Querying the SOLR Index
- System Metadata Index Properties
- Properties of the Index Derived from Resource Maps
- Values Extracted from Science Metadata
- Date Representations in Science Metadata Documents
- Science metadata examples
- Standard Specific Metadata Extraction Notes
- Attribute Descriptions and Notes
- Creating Citations from Index Fields