Use Case 02 - List PIDs By Search¶
- Revisions
- View document revision history.
- Goal
- Get list of PIDs from metadata search (anonymous and authenticated).
- Summary
A user performs a search against the DataONE system and receives a list of object identifiers (PIDs) that match the search criteria. The list of PIDs is filtered such that only objects for which the user has read permission will be returned.
Content discovery in DataONE is achieved primarily through the service interfaces provided by the Coordinating Nodes. Other systems may index content available in DataONE (UC36), though the operation of those systems is out of scope for DataONE operations except that the exposed APIs enable such functionality.
- Actors
- Client performing search operation
- Coordinating Node
- Preconditions
- Client has authenticated to at the desired level (e.g. client may not have authenticated, so access might be anonymous).
- Triggers
- A search is performed against the DataONE system
Post Conditions
- The client has a list of PIDs (
Types.objectList) for which they have permission to read and match the supplied query or an error condition.- The log is updated with information about the request
Figure 1. Use case 02.
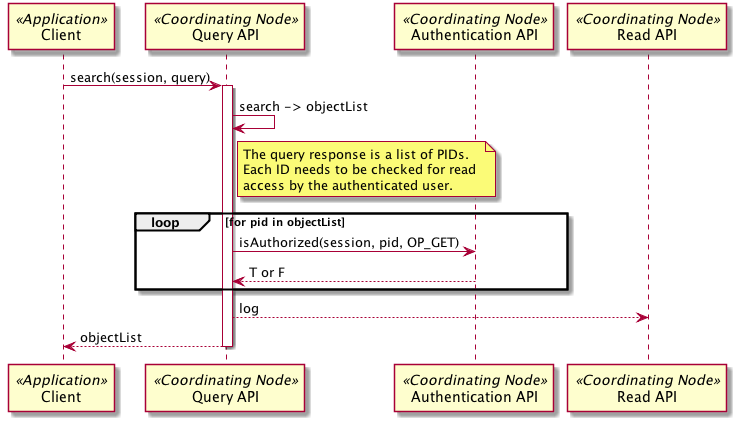
Figure 2. Interaction diagram for Use Case 02. The process for determining READ access is for illustration purposes only. Actually implementation may vary (e.g. by augmenting the query used for searching).
Notes
lots of stuff buried in query. What information/interface is needed for resolution/expansion of the query? For example a particular user may be identified with a particular community which uses a particular ontology. Where are things like ontologies maintained and where are the interfaces between these and searches maintained? Searches need to be able to respond to the dynamic nature of domain ontologies. Does the ontology need to have authorization tied to it? A use case would be an ontology which is under development and not ready for general distribution. Another case might be where the ontology contains representations of human subject information, meaning that “cancer survivors” includes this list of people. Or where the ontology provides geospatial information about restricted information (locations of USFS FIA plots). Similar issues apply to T&E species information.
Group structure representation: A user is a member of zero to many groups, authorization may be carried with that group membership. This is down in the verify API, which needs to take into account group membership and group permission inheritance. Question: What is the resolution for conflicting access permissions?
Q. Can a query be done at a member node? The diagram implies that the query is only done at a coordinating node. A member node may have a subset (or the full set) of metadata and the user may wish to do the search only at a member node, knowing that the subset is restricted to data relevant to a community of practice.
A. First iteration will provide query service on CNs, though nothing to prevent MNs implementing query as well.
Where is the filtering done for the results, in terms of when does the result set get filtered to those which the user can see?
Q. Does the model allow the query service to do two searches and union the results? The first query might be against the set of records known to be publicly readable, with a follow-on query against the set of records known to have restricted access. Is this envisioning the query service generating a set of results (against the restricted records) and passing that list to the authorization API, or is this envisioning a one by one situation. Or does the authorization API pass back to the query service the list of records that the user is authorized to see, and that gets anded with the result set.
A. The resultset is a list of PIDs that needs to be vetted for read access. Hence query results can be merged (union) or joined as the output from such operations is always a list of PIDs that will be vetted for read access.
How distributed is the database of users and their authorization records?
Q. Does the coordinating node have to know all authorization records, with that being replicated? Or is some amount of the authorization maintained by (for example) the “owning” member node and the search system may need to contact multiple authorization authorities for the records in a particular result set? It also implies that if the authorization information is at the coordinating node, that the authorization authority needs a means to validate the replicated authorization information to ensure that the info at the cn is up-to-date.
A. One scenario is that all authorization information is stored in the system metadata with each object. Then authorization can be performed by MNs or CNs.
Q. Why does step 4 need to validate the token, given that the token was generated in step 2?
A. This is normal security validation of all user inputs once those have gone out of the control of the issuing service. Also applies to cases where tokens have a specific lifetime, and the token may be valid, but expired. Authorization token lifetimes are important for both interactive sessions and for cases like workflows, where the session may run for days.
What logging level is required for the operation? Should the search appear as a hit against each object? Just log the query (and perhaps who did it)?
![]()