DataONE Overview¶
The major goal of NSFs DataNet program is to catalyze development of a system addressing the vision outlined in Chapter 3 (Data, Data Analysis, and Visualization) of NSF’s Cyberinfrastructure Vision for 21st Century Discovery [2] in which “science and engineering digital data are routinely deposited in well-documented form, are regularly and easily consulted and analyzed by specialists and non-specialists alike, are openly accessible while suitably protected, and are reliably preserved.” The DataNet project DataONE (Data Observation Network for Earth) is a federated data network built to improve access to Earth science data, and to support science by: (1) engaging the relevant science, data, and policy communities; (2) facilitating easy, secure, and persistent storage of data; and (3) disseminating integrated and user-friendly tools for data discovery, analysis, visualization, and decision-making.
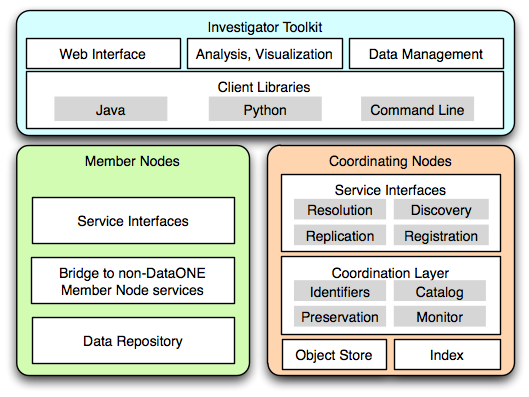
Figure 1 An overview of the major components of the DataONE architecture.
There are three major components in the DataONE infrastructure: Member Nodes which represent data repositories, Coordinating Nodes which serve data management and discovery services, and the Investigator Toolkit which contains a variety of end user tools for interacting with the infrastructure.
Participation in the DataONE infrastructure as a Member Node or by using the Investigator Toolkit (i.e. implementing or utilizing DataONE service interfaces) provides several fundamental services upon which additional infrastructure, services, applications and communities may be built. These core, community building services include:
- promotion of data preservation through automated replication of data and metadata
- support for arbitrary globally unique identifiers with guaranteed resolution and dereferencing
- extensible search and discovery services
- federated management of user identities and access control
Member Nodes are primarily existing data repositories (e.g. Dryad, the Knowledge Network for Biodiversity, ORNL DAAC) that already fill an important role in their respective communities supporting data management, curation, discovery and access functions. Existing or new repositories can participate in the DataONE infrastructure by implementing a simple set of APIs (Application Programming Interfaces) which represent a convergence of functionality expressed in a variety of existing systems. These APIs include basic operations such as listing and retrieving objects, support for creation of content, and the ability to generate low level system metadata describing the various objects (data, metadata) exposed by the service. Member Nodes may implement a subset of the full suite of Member Node APIs, and in this way participate in the network with minimal effort (e.g. as a “read only” data source). Member Nodes that implement the full suite of APIs will be able to accept data from other Member Nodes which in turn assists with data preservation by ensuring multiple copies of all content are available, thus reducing the risk that content will be lost or inaccessible if a Member Node should go offline.
Member Nodes may eventually number in the thousands as progressively smaller repositories come online, perhaps even to the level of individual labs deploying their own Member Node to take advantage of the broad infrastructure enabled by DataONE.
Coordinating Nodes implement critical services through the APIs that enable identifier resolution, data preservation, data discovery, and supplement the federated identity system. Coordinating Nodes replicate all content between themselves, an in doing so create a small set (3-6 nodes) of geographically and institutionally isolated systems that ensure ongoing operation of the infrastructure should any particular node be inaccessible. Coordinating Nodes maintain complete copies of all science metadata (detailed descriptions of science data objects and collections) and system metadata (low level metadata describing the type, size, ownership, and locations of data and) and index this information to enable data discovery services.
Investigator Toolkit is a suite of software libraries, tools, and applications that support interaction with the DataONE infrastructure through the REST service APIs exposed by the Coordinating and Member Nodes. Low level libraries are initially available in Python and Java which assist application developers to take advantage of the core services exposed by DataONE participants. For example, an R plugin has been developed using the Java library. Enabling this plugin within a R script enables discovery, retrieval, and storage of content directly in the DataONE infrastructure. Similar extensions are being developed for workflow tools such as Kepler, VisTrails and Science Pipes to enable interaction with the core DataONE services.
The implementation roadmap of DataONE targets an initial public release of the core cyberinfrastructure towards the end of 2011, with considerable emphasis on stable implementation of the core services. At that point, the infrastructure will support content replication, identifier resolution, content discovery and retrieval, and a significant proportion of the federated identity infrastructure. The Investigator Toolkit will contain several components widely used by the community, and at least six significant data collections will be participating as Member Nodes. Several relatively minor subsequent releases will provide incremental enhancements to core capabilities. Additional Member Nodes will be progressively added to the infrastructure as resources permit- some repositories may have resources to independently implement the necessary APIs, others may require assistance from the DataONE development team.